Abstract
Models for student reading performance can empower educators and institutions to proactively identify at-risk students, thereby enabling early and tailored instructional interventions. However, there are no suitable publicly available educational datasets for modeling and predicting future reading performance. In this work, we introduce the Enhanced Core Reading Instruction (ECRI) dataset, a novel largescale longitudinal tabular dataset collected across 44 schools with 6,916 students and 172 teachers. We leverage the dataset to empirically evaluate the ability of state-of-the-art machine learning models to recognize early childhood educational patterns in multivariate and partial measurements. Specifically, we demonstrate a simple self-supervised strategy in which a Multi-Layer Perception (MLP) network is pre-trained over masked inputs to outperform several strong baselines while generalizing over diverse educational settings. To facilitate future developments in precise modeling and responsible use of models for individualized and early intervention strategies.
Dataset
The ECRI dataset is a longitudinal dataset specifically designed for modeling and predicting future reading performance in early childhood education. The dataset includes:
- Demographic Data: Includes student-level information such as special education status, gender, and age.
- Assessment Data: Includes various reading assessments, such as Dynamic Indicators of Basic Early Literacy Skills (DIBELS), Stanford Achievement Test, and Woodcock Reading Mastery Test.
- Intervention Data: Records the intervention provided to students identified as at-risk for reading difficulties.
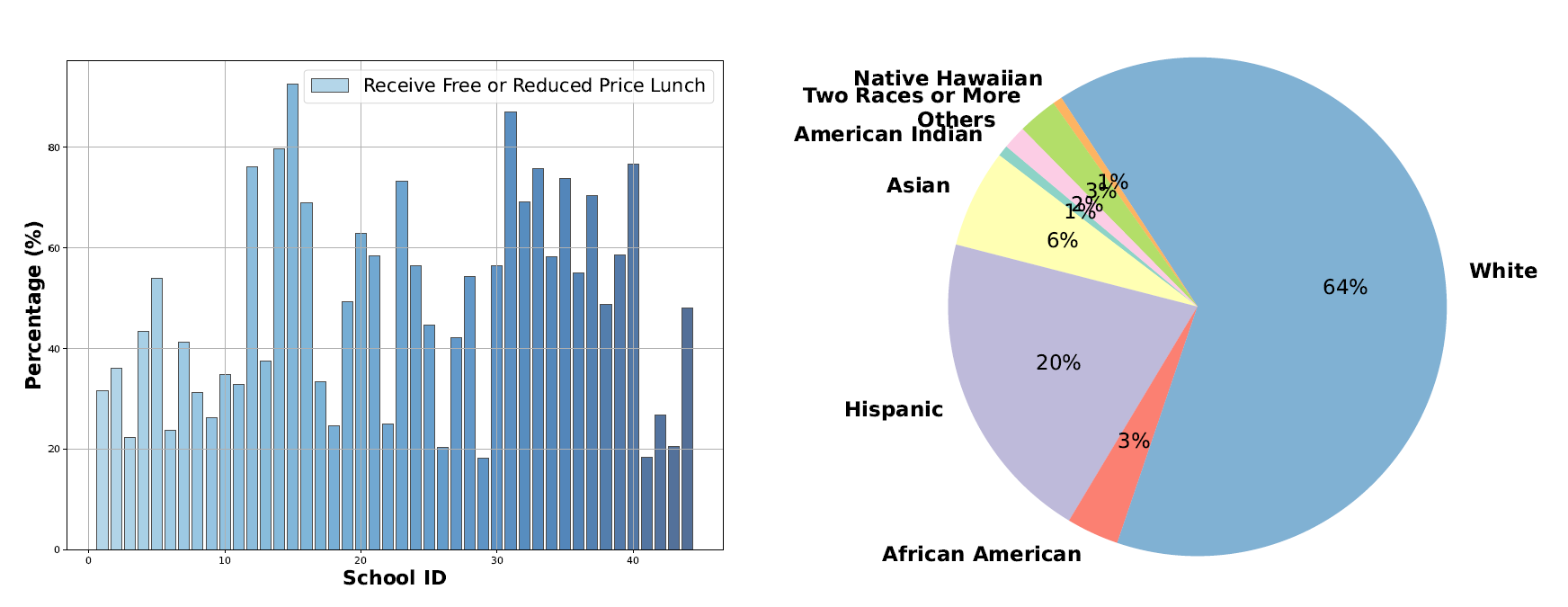
Visualization of School-level Features. Left: the percentage of schools providing free/reduced-price lunch. Right: student demographics, averaged over schools.
Parameter Definition
| Parameter | Definition |
|---|---|
Gender |
Indicates the gender of student. |
Tx |
Binary variable indicating if the student is in control or intervention group. |
Age1b |
Age of student. |
Tier2_N |
Number of at-risk readers in class. |
grp_rate |
Rate of group practice. |
rcmistot |
Total score of Ratings of Classroom Management and Instructional Support. |
gnrl_fid |
Fidelity of implementation. |
TKPctCrt |
Percentage answered correctly in Teacher Knowledge Survey. |
NWFcls |
Score for correct letter sounds for Nonsense Word Fluency measure. |
NWFwrc |
Score for words recoded completely and correctly for Nonsense Word Fluency measure. |
ORFwc |
Number of words read correctly in one minute for Oral Reading Fluency measure. |
SAwrS |
Word reading score for Stanford Achievement Test. |
SAsrS |
Sentence reading score for Stanford Achievement Test. |
SAtoS |
Total reading score for Stanford Achievement Test. |
RMwidRS |
Score on Word Identification for Woodcock Reading Mastery Test. |
RMwdaRS |
Score on Word Attack for Woodcock Reading Mastery Test. |
Method
Models for student reading performance can empower educators and institutions to proactively identify at-risk students, thereby enabling early and tailored instructional interventions. However, there are no suitable publicly available educational datasets for modeling and predicting future reading performance. We leverage the ECRI dataset to empirically evaluate the ability of state-of-the-art machine learning models to recognize early childhood educational patterns in multivariate and partial measurements. Specifically, we demonstrate a simple self-supervised strategy in which a Multi-Layer Perception (MLP) network is pre-trained over masked inputs to outperform several strong baselines while generalizing over diverse educational settings. To facilitate future developments in precise modeling and responsible use of models for individualized and early intervention strategies.
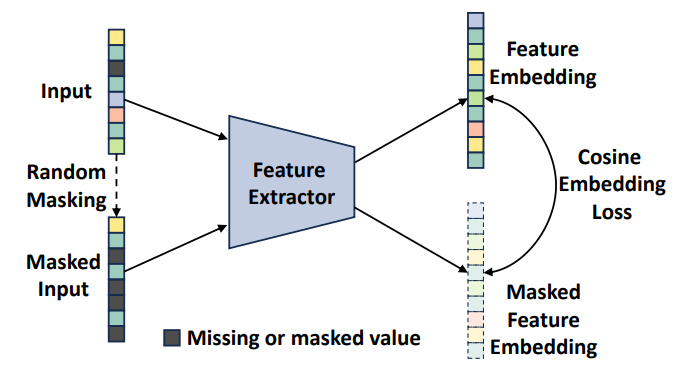
Model Framework. We randomly mask parts of the input variables, i.e., as missing values, and train the model using a loss derived from both the original and masked input to a common feature extractor (we employ a cosine embedding loss to enforce similarity among the two embeddings).
Results
In our study, we utilize both demographic and assessment-based features to predict the specified target in word identification or word attack tasks. we extensively benchmark diverse ML approaches that can be used for predicting early childhood education students’ reading performance.
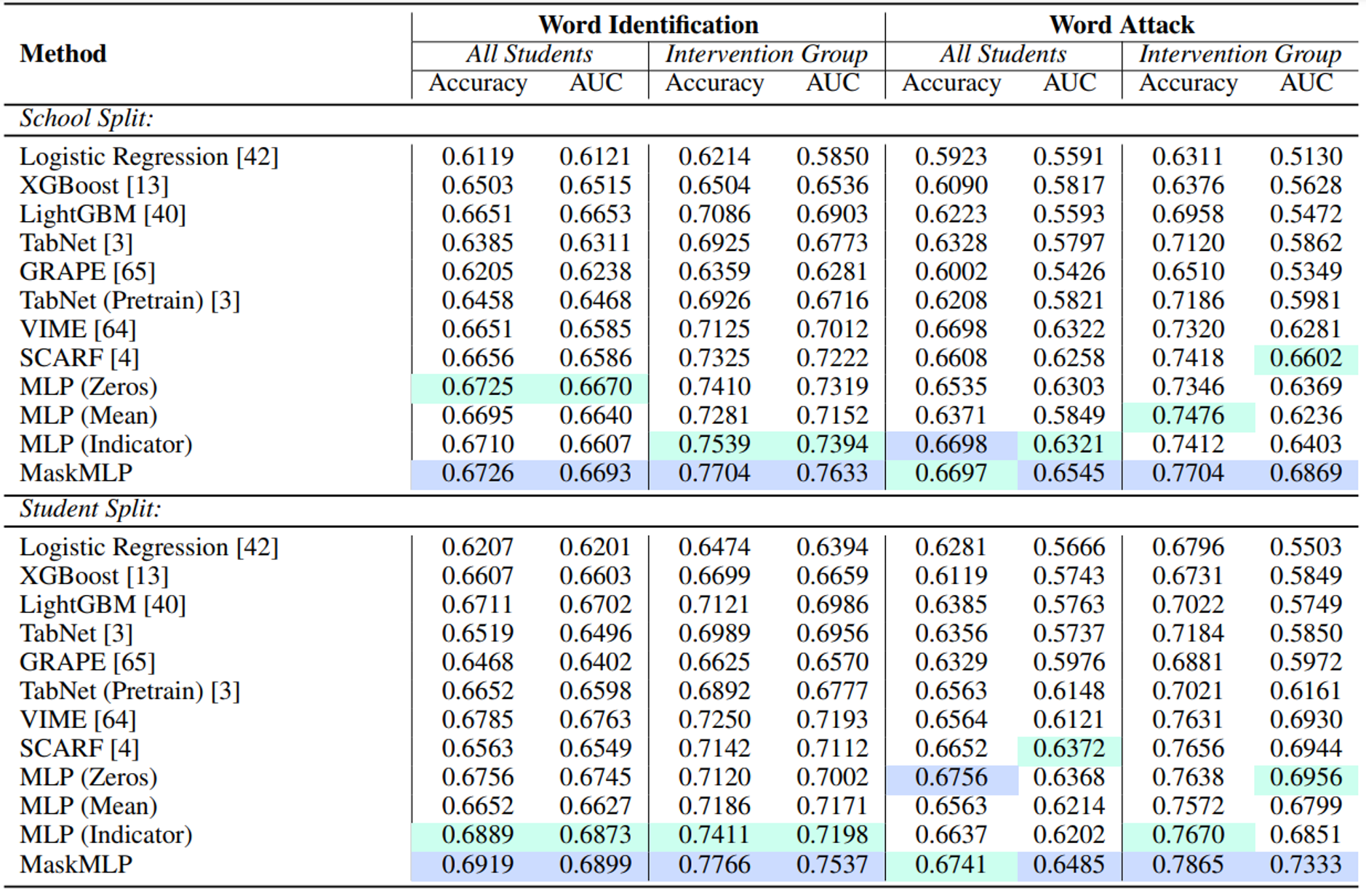
Results on the ECRI Dataset. We report model performance for the two main
reading skill prediction tasks over different generalization settings. School-split enforces disjoint
schools in training and testing, while student-split allows students within the same school to be in the
training and testing split. Model performances are shown for the entire set of test students and over
the intervention subset (received additional instruction time). The best results are shown in blue and
the second best result is shown in green.
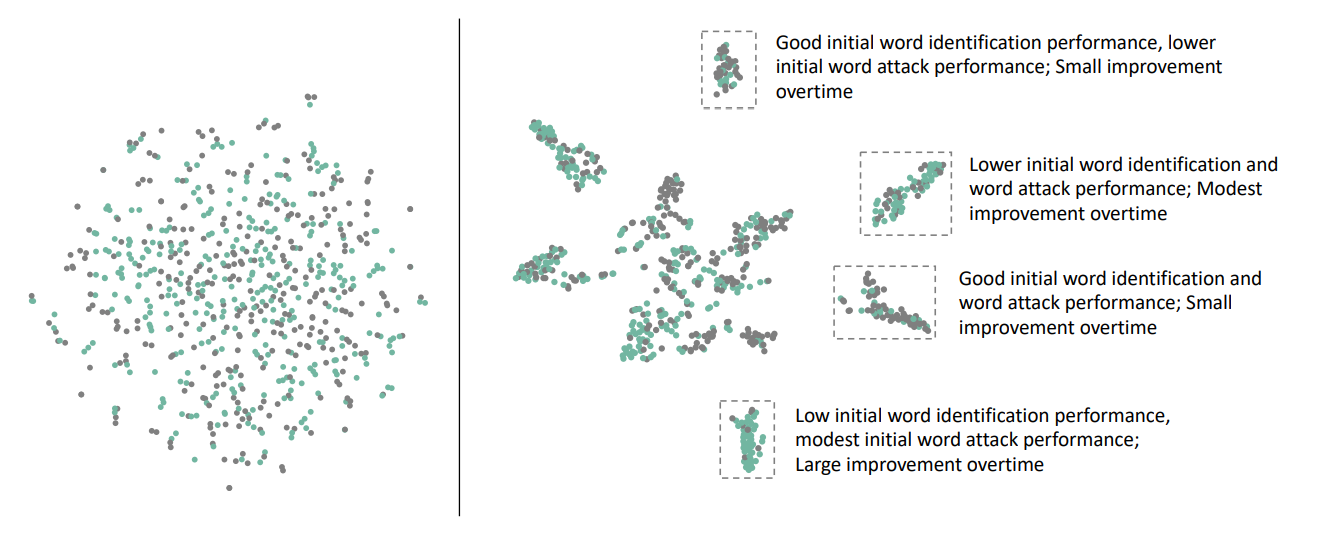
Visualization of t-SNE-based Embedding and Student Profile Analysis. The visualization uses embeddings derived from the MLP (left) and MaskMLP (right) models for the word identification task, with negative samples shaded in gray and positive samples shaded in green. The pre-training step in MaskMLP results in an embedding with greater separation among student profiles.
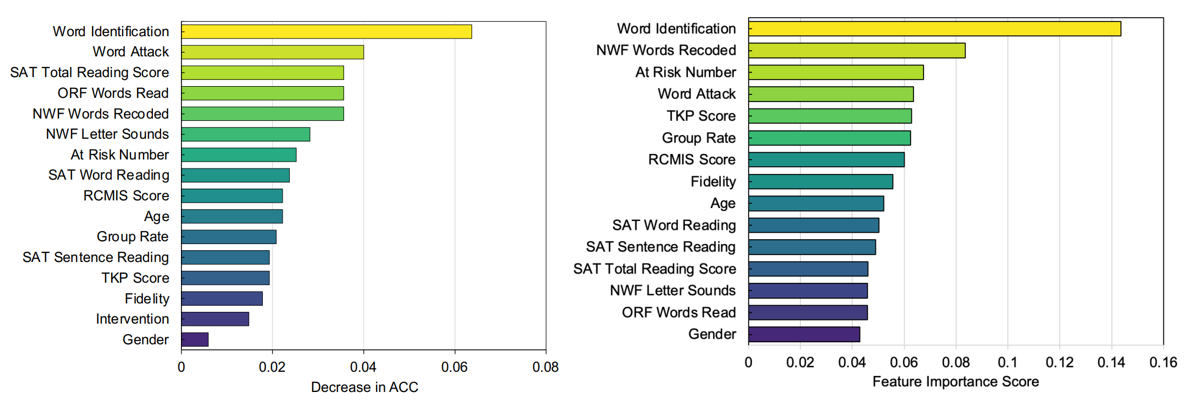
Visulization of Feature Importance on Word Identification Task. Left: feature importance of MaskMLP; Right: feature importance of XGBoost.
Acknowledgments
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The research reported here was supported by the Institute of Education Sciences, U.S. Department of Education, through Grant R324A090104 to the University of Oregon, and a Red Hat Collaboratory research award. The opinions expressed are those of the authors and do not represent the views of the Institute of Education Sciences or the U.S. Department of Education.
BibTeX
@inproceedings{shangguanscalable,
title={Scalable Early Childhood Reading Performance Prediction},
author={Shangguan, Zhongkai and Huang, Zanming and Ohn-Bar, Eshed and Ozernov-Palchik, Ola and Kosty, Derek and Stoolmiller, Michael and Fien, Hank},
booktitle={The Thirty-Eighth Conference on Neural Information Processing Systems Datasets and Benchmarks Track},
year={2024}
}